“True! --nervous --very, very dreadfully nervous I had been and am; but why will you say that I am mad? The disease had sharpened my senses --not destroyed --not dulled them. Above all was the sense of hearing acute. I heard all things in the heaven and in the earth. I heard many things in hell. How, then, am I mad? Hearken! and observe how healthily --how calmly I can tell you the whole story.”
This distraught character from Edgar Allan Poe’s The Tell-Tale Heart begins with a sense of immediacy that compels the audience to listen, providing the engaging sort of material that we like to bring readers of Duolingo Stories. But our learners come from a range of second-language reading proficiencies, and so we grapple with the task of adapting such material into simpler forms, while retaining its substance. For instance, we might rewrite the above passage into the following text, aimed at beginner English language learners:
“It’s true! I am very nervous, but crazy? I was sick, but I could hear much better. I could hear everything in heaven, earth, and hell. How could I be crazy? Listen and I will tell you the whole story.”
This text adaptation task poses a difficult challenge for us in efficiently producing accessible content for learners from many levels—not only for our Stories, but also for Podcasts and other features across Duolingo products. So, we’ve built semi-automated machine learning systems to aid in our content creation process targeting various language proficiencies, as measured by the CEFR standard. In particular, we’ve built the CEFR Checker to help transform and check that content across languages appropriately targets beginner, intermediate, and advanced learners. Today, we’re making this tool available to language educators and the general public as well! Its use and methodology are described in some detail below.
CEFR and the checker
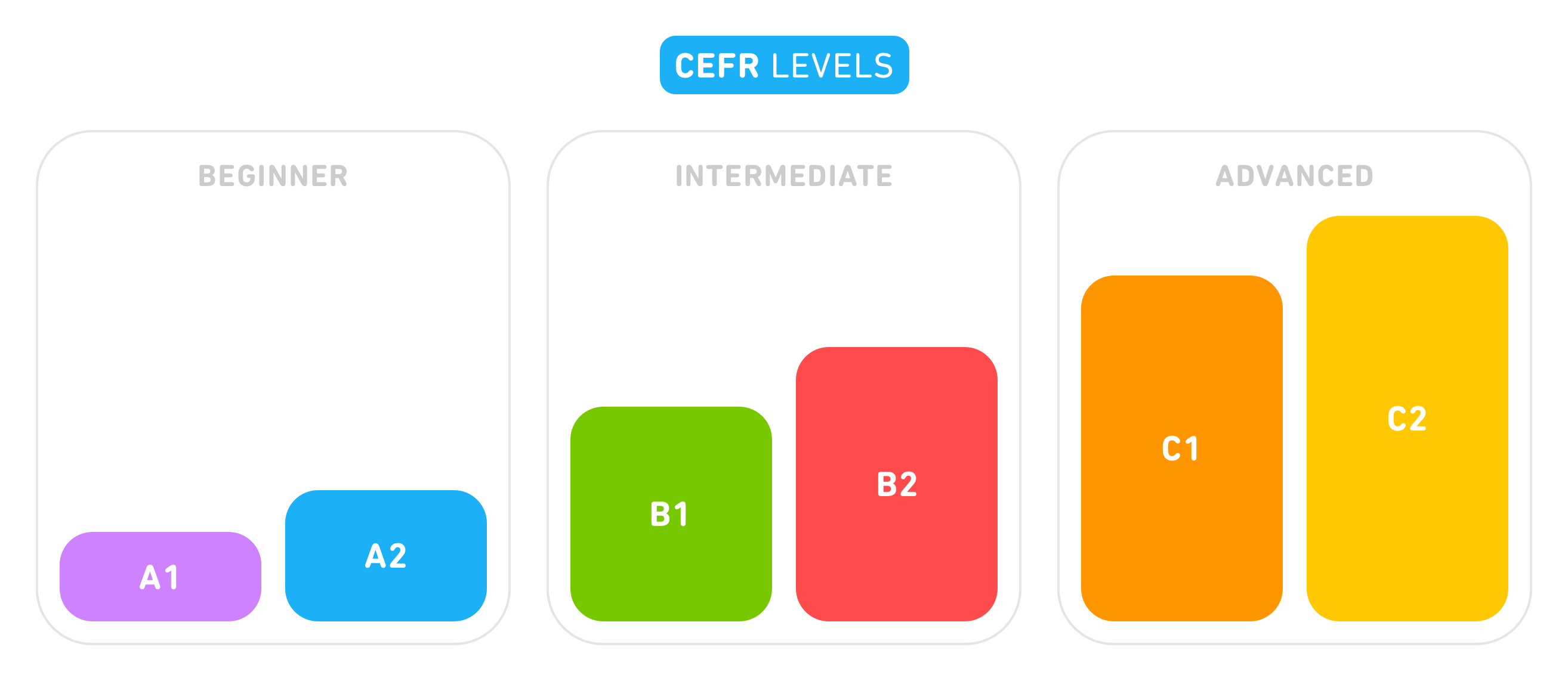
The CEFR (Common European Framework of Reference) is a language proficiency standard that classifies learners into beginner, intermediate, and advanced levels of competence with respect to the language that they’re learning. These levels are conventionally labeled A1, A2, B1, B2, C1, and C2—corresponding to the various levels of proficiency as pictured above. The level of a learner is assessed with respect to communicative competences in listening, reading, writing, and speaking by evaluation learners according to “Can do…” statements. These statements range from “Can understand and produce basic greetings” (at a beginner level) all the way up through “Can produce well-structured detailed text on complex subjects” (at a more advanced level).
Given the CEFR standard, we can think of our adaptation task in terms of modifying a piece of text that’s accessible to an intermediate learner (e.g., B1) into a text with the same content, but accessible to a beginner (e.g., A1 or A2). We even need to adapt A2 down to A1 sometimes! This often requires simplifying the vocabulary, grammar, or idiomatic and culturally-dependent aspects of the language into forms that are more easily comprehensible to learners at different levels. Our CEFR Checker aids in this process by estimating the CEFR level at which a learner might comprehend each word in a proposed revision of a text. For example, the screenshots below show how the tool estimates that several words in the original Edgar Allan Poe sample are at a C1 or C2 level—highlighted in red—whereas the most advanced single word in the simplified text (“nervous”) is estimated at a B1 level—highlighted in light orange.


The tool provides these CEFR estimates for hundreds of thousands of words in English, Spanish, French, Italian, German, and Portuguese, and we are releasing two of these languages (English and Spanish) in a public version today! We’re able to provide these estimates across such a large vocabulary and multiple languages by leveraging the AI machine learning model described below.
The AI part
The colorful text visualization in the CEFR Checker depends on the CEFR levels for hundreds of thousands of words across several languages—which would be extremely costly and maddening for our curriculum experts to label by hand. We reduce this cost by training a machine learning system on a few thousand hand-annotated CEFR labels for words in English, Spanish, and French, and allowing that model to generalize to hundreds of thousands of words across many other languages. This ordinal regression learning model takes a word and its source language, and predicts the estimated CEFR level (A1, A2, B1, B2, or C) of a target learner of the word.
We use transfer learning and domain adaptation techniques while relying on language-agnostic features to generalize the model to new languages. Namely, the features in the model include multilingual word embeddings (MWEs) and corpus frequencies estimated on movie subtitles. The MWEs map words into a 300-dimensional space where words that appear in similar functional and semantic contexts across multiple language corpora will tend to be near each other, providing a language-agnostic representation of a word’s “meaning” as demonstrated by the simplified, 3-dimensional space depicted below.
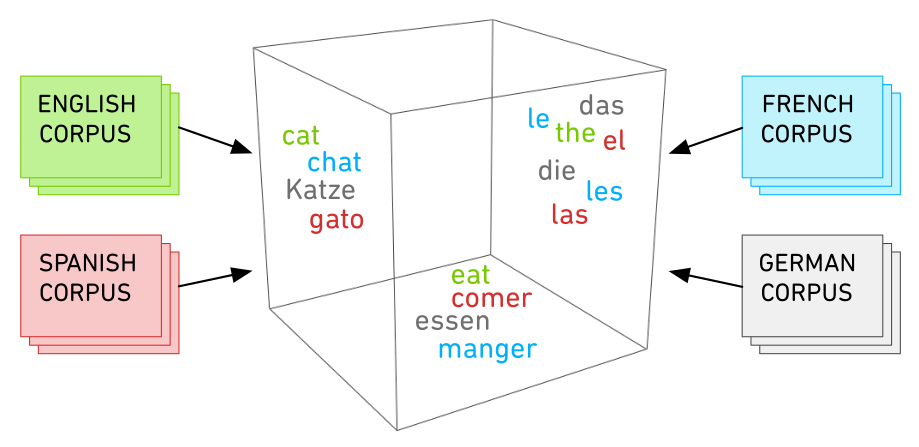
These MWE and the corpus frequencies seem intuitively well-motivated by the fact that the CEFR tends to require communicative competences that depend on topical, semantic information (e.g. whether a person can interact in “everyday” contexts involving greetings, personal life, food, family, etc), and we expect these competences to be arranged such that learners become familiar with frequently occurring linguistic forms prior to rare linguistic forms.
Why bother with all the AI stuff? Why not simply translate an English CEFR wordlist into other languages? Consider that in English we say, “I am hungry,” but in Spanish you say, “tengo hambre” (which literally means “I have hunger”). Both expressions are at the A1 level. However, If we just translate expressions like these word-by-word from one language to the other, we would end up with the Spanish adjective hambriento (“hungry”) or the English noun hunger (“hambre” in Spanish), which are actually both B1. Among other things, this mismatch of idiomatic expressions among languages makes it hard to simply translate wordlists; we’ve found that our approach of modeling frequency and semantics helps us do a much better job.
Conclusion
The CEFR Checker has been a critical part of our process in adapting content for learners across many target languages and proficiencies. We hope that its release might be helpful for other curriculum developers building language learning resources beyond Duolingo, and that its existence sparks further NLP and machine learning research geared toward applications that feed into similar tools. Also, if you’re interested in helping us build and improve these sorts of tools that support language learning, we hope that you apply for our open machine learning and research positions here.