Presidential debates are performances. The stage is lined with podiums. The candidates, who are greeted with an applause upon entering from stage left or right, are dressed in clothing designed to help the audience identify their character. Some candidates opt for suits and dresses in bold, saturated colors. Some candidates wear cufflinks. And some candidates use bold ties to distinguish themselves, while others don’t wear a tie at all. What unites every candidate on stage is that they’ve been rehearsing their lines for weeks.
The words that a candidate chooses are as deliberate as the color of their tie – and some words are more infrequent than others. For example, only a small portion of the general population may recognize that myocardial infarction is the technical term for a heart attack. When words are “less accessible”, they are also usually identified as more advanced vocabulary words for second language learners according to the standards set forth by the CEFR, or the Common European Framework of Reference for Languages. Using a more sophisticated vocabulary isn’t necessarily detrimental; just like in college application essays, strategically employing technical terminology can help signal that we have deep domain knowledge or expertise on a particular subject matter. And the stakes become even higher when competing for the highest office of the United States.
The CEFR provides a common, internationally-recognized standard for discussing language proficiency. Each level progressively indicates a higher level of proficiency.
At Duolingo, we use CEFR levels to describe the potential difficulty of content presented in our language courses and other learning content such as Duolingo Stories and our Spanish and French Podcasts. One tool we leverage for identifying the difficulty of our learning content is the CEFR Checker, which was developed by a team of machine learning engineers at Duolingo. CEFR Checker is an AI tool that allows users to gauge the CEFR level of a body of text, as well as predicted CEFR levels of each unique word.
We can also leverage the CEFR Checker to measure the distinct language choices each of the candidates has made during the Democratic debates over the past few months.
Where the Candidates Land
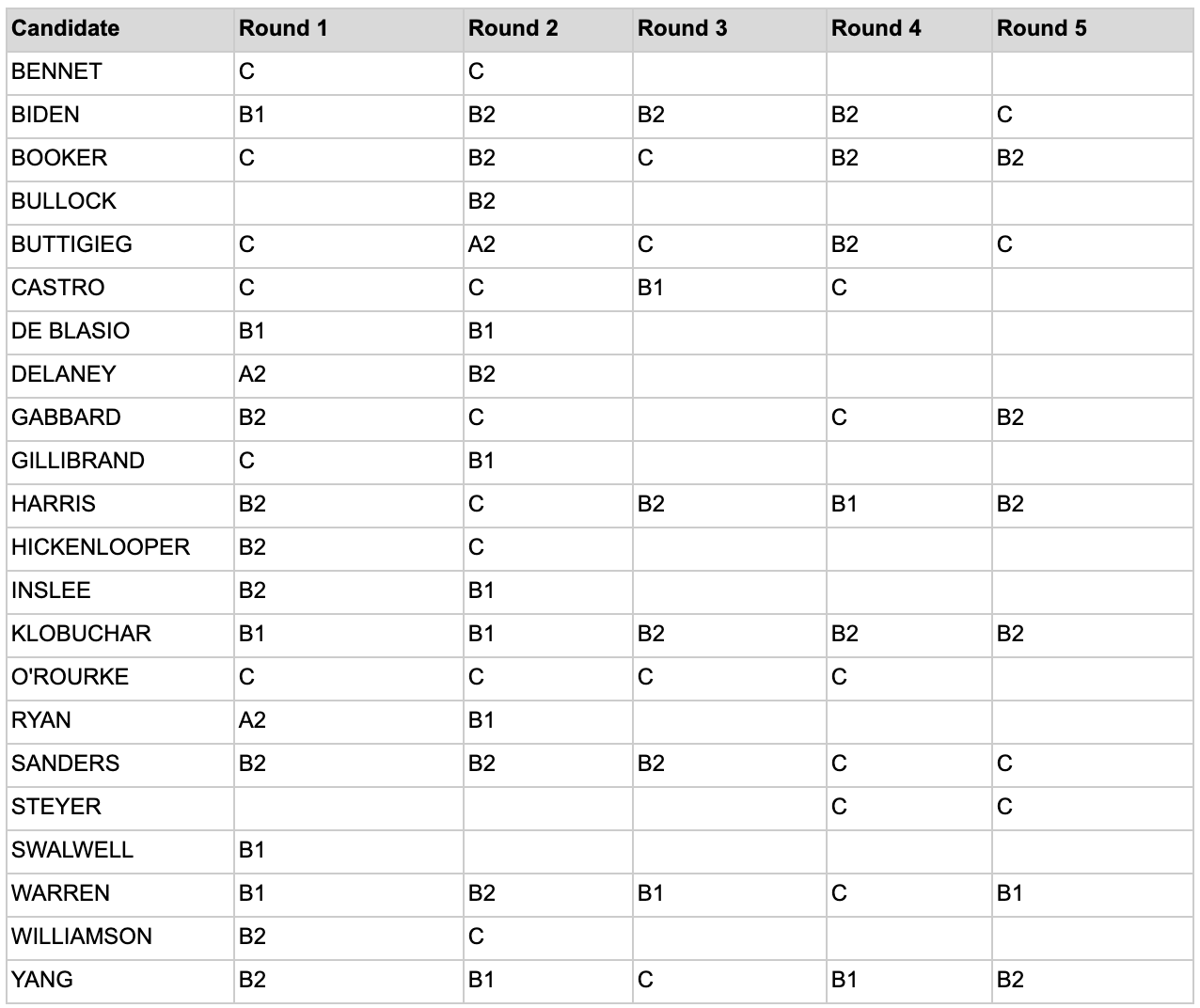
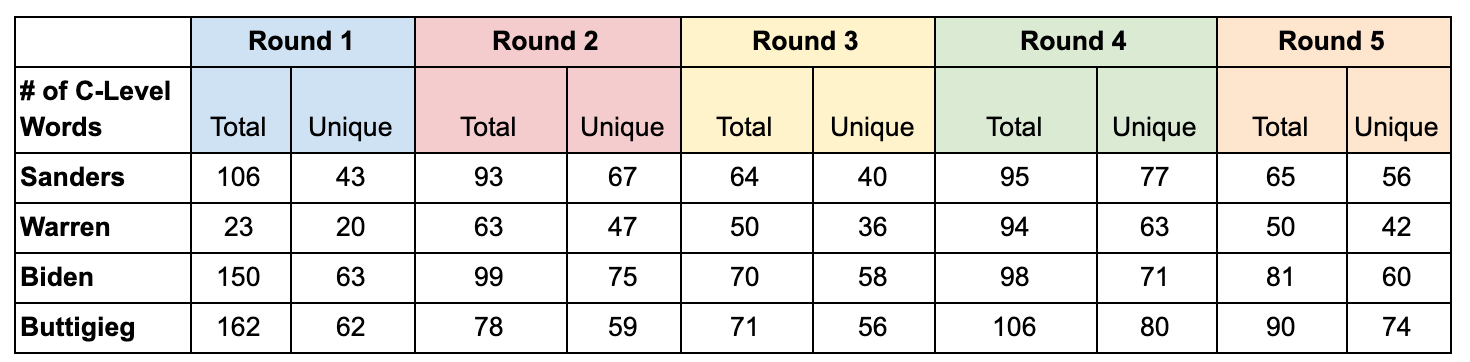
Using publicly available transcripts, everything a candidate said during each debate was combined into a single “monologue” and fed into the CEFR Checker. The CEFR Checker then returned the CEFR level estimate associated with each candidate’s “monologue” as well as the CEFR level of each word that was spoken. Other data points, such as the total vs. unique words words spoken at each level, were also captured. One point to note is that the CEFR Checker bundles all C1 and C2 content into a single tier, which is simply C.
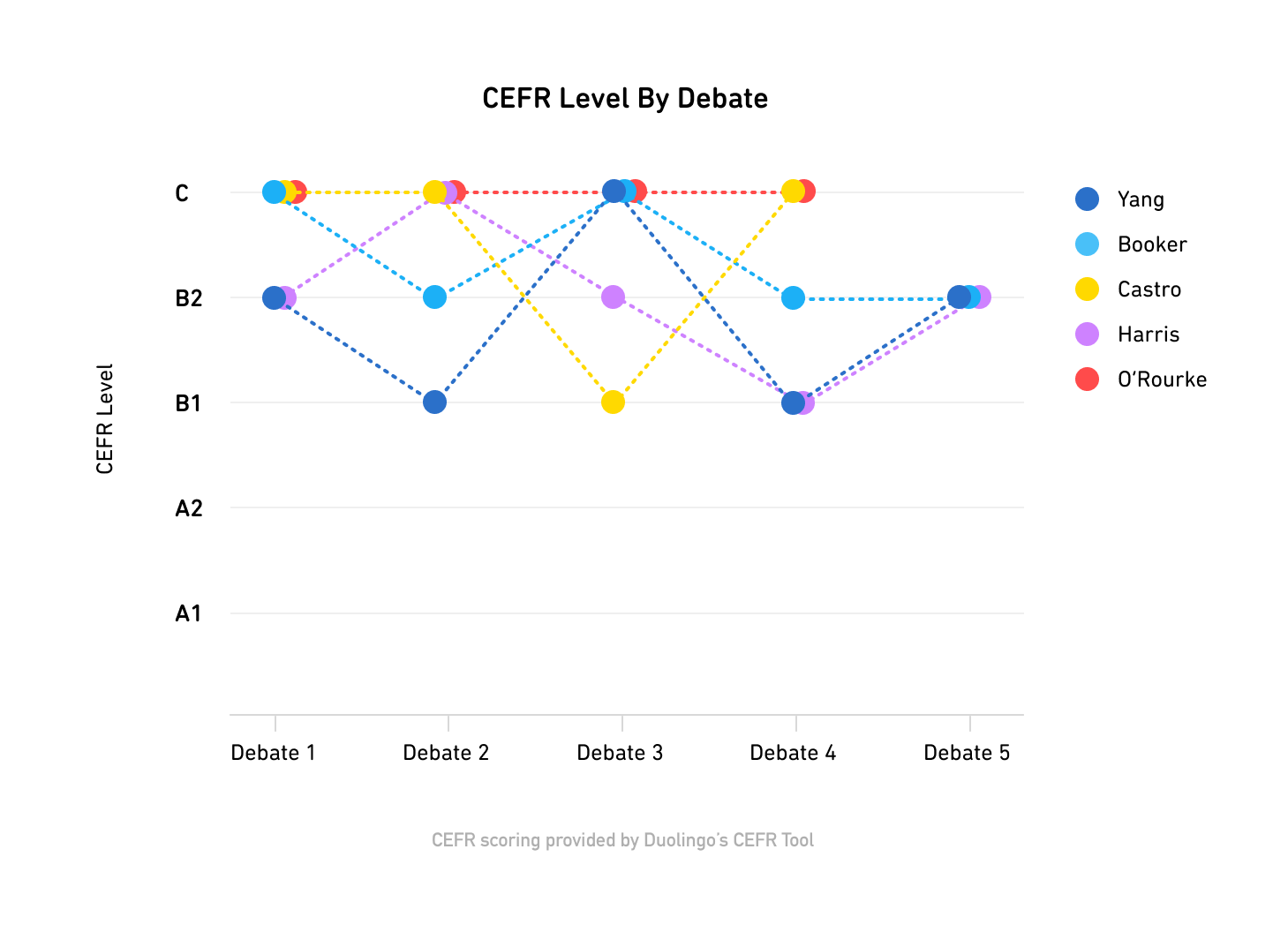
After the first debates in June 2019, Joe Biden, Bernie Sanders, and Elizabeth Warren – all candidates with decades of political experience – landed in the B (Intermediate) range. On the other hand, Cory Booker, Pete Buttigieg, Julian Castro, Kirsten Gillibrand, and Beto O’Rourke – all candidates with much fewer years of experience in politics, by comparison – landed in the C (Advanced) range.
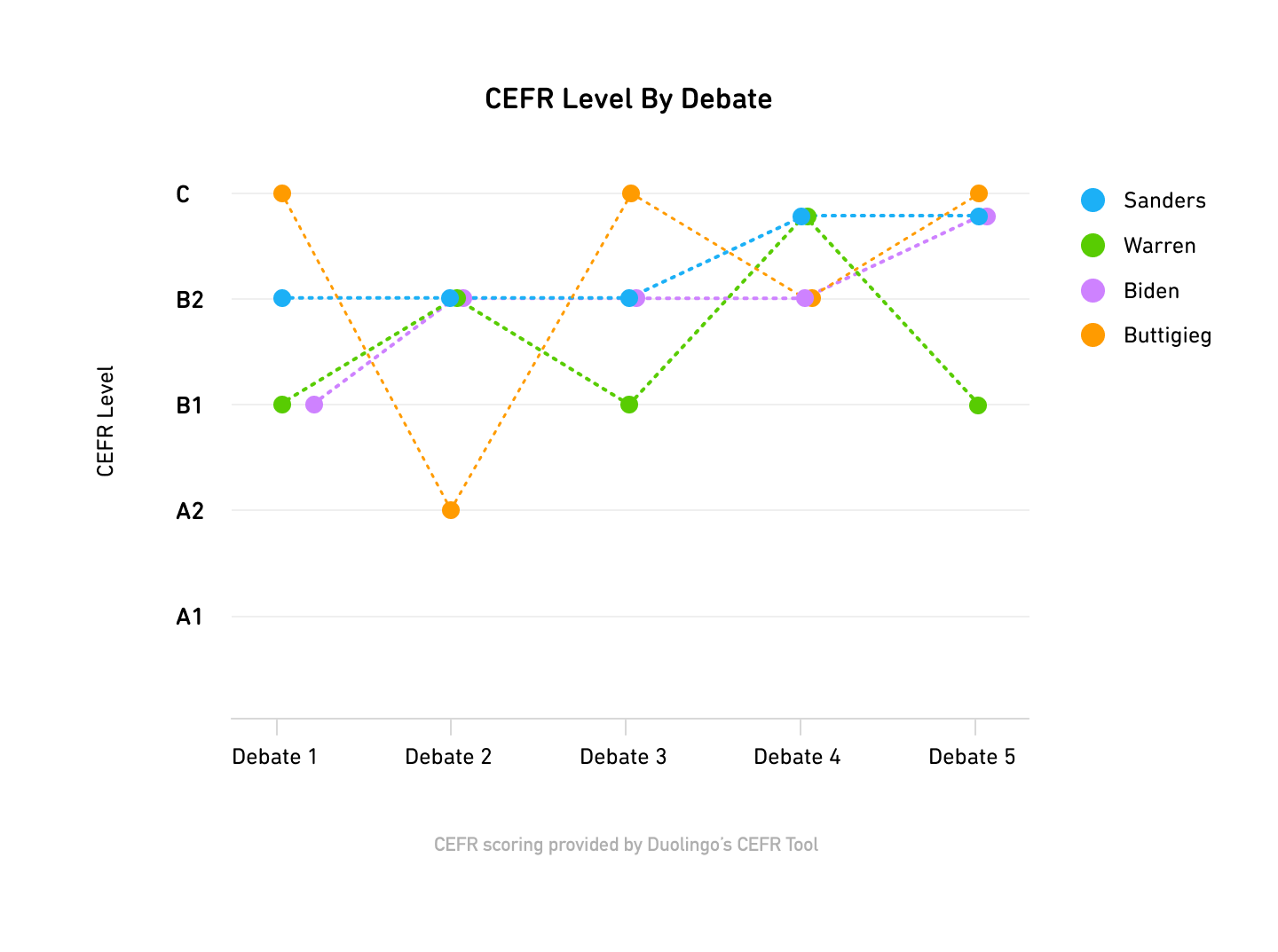
Sanders and Warren Flip the Script
During the fourth debate on October 15, 2019, Sanders and Warren both suddenly jumped into the ‘C’ level bracket.
Although it’s easy to explain this jump as a byproduct of questions on more advanced subject matter (e.g., the possible impeachment of the current sitting president, Donald Trump), not all candidates suddenly started speaking at a higher level: Biden remained at the same level as the previous two debates, while Booker, Buttigieg, and Andrew Yang’s CEFR levels all decreased.
The CEFR Checker doesn’t just provide an estimate of which CEFR level best describes a body of text – it can also return the estimated CEFR level for individual words. After analyzing the frequency of the individual words used by candidates, we were able to see which C-level (advanced) words candidates were using the most.
Because Sanders and Warren both suddenly adjusted how they spoke during the October 2019 debate, we specifically looked at the top C-level words both candidates used by total frequency throughout all of the debates. Ignoring words that are commonly used within the genre of debate speech (e.g. Republicans and Democrats) as well as acronyms (NRA) that presented a less meaningful signal, we discovered that Warren suddenly increased the number of times she said corporations, loyalty, and impeachment. Sanders, on the other hand, did not appear to increase the frequency of any C-level word as dramatically.
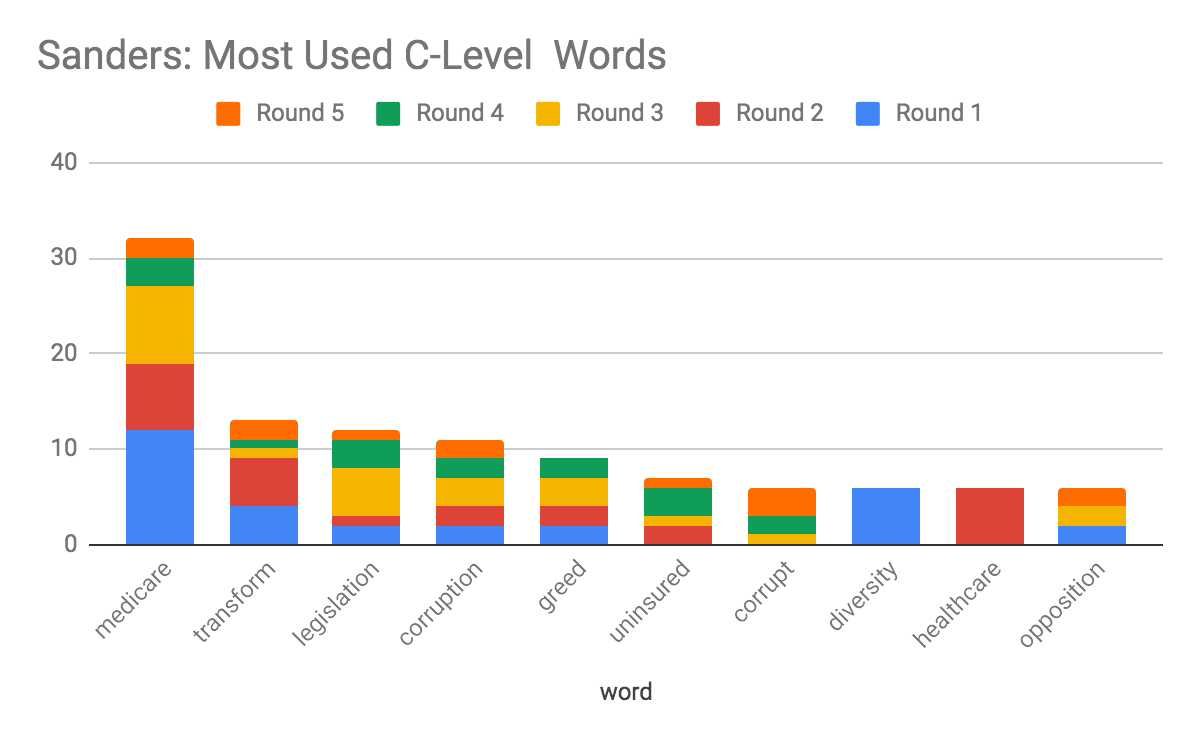
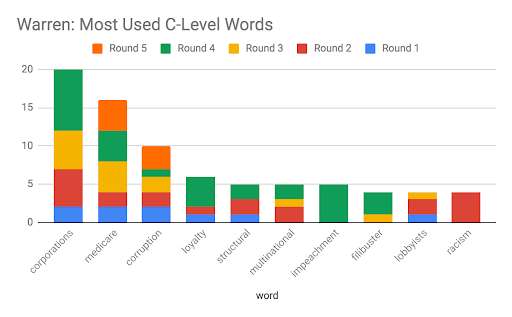
Digging into C-level word counts for each candidate, we observed that that although both Sanders and Warren increased the number of total and unique C-level words, Sanders’ number of unique C-level words increased more than Warren’s. In other words, during the October 2019 debate Warren likely repeated the same C-level words while Sanders used a greater variety of C-level words. Some of the vocabulary words that Sanders used for the first time during the debate included moral, reassure, divisiveness, epidemic, comprehension, and opioids.
Other Observations
Most Consistent
O’Rourke was by far the most consistent in his speaking habits; he consistently hovered at C.
Most Interesting Trend Line
Since the second debate, Kamala Harris has trended towards a lower-intermediate CEFR level – stepping down a CEFR level after each subsequent debate until Debate 5 when she ended her campaign at B2.
A Similar Pattern
Buttigieg, Booker, and Yang all roughly follow the same pattern. All three dropped their speaking levels during the 2nd and 4th debates. Buttigieg had the most pronounced start at C during Debate 1, then dropped down to A2 during Debate 2, before jumping up to C again during Debates 3 and 5.
The Final Act
The CEFR score associated with each candidate doesn’t indicate their intelligence or lexical sophistication off the debate stage. CEFR is an estimate of the expected proficiency at which we would expect a second-language learner to be able to use the word in some way.
With that being said, CEFR Checker does provide a way to measure and track the distinct language choices of each candidate throughout the debates. And, just like Yang’s notably absent tie and Gabbard’s white pantsuit, the words each candidate have strategically employed throughout the debates are carefully chosen to represent key aspects of their character. While it's impossible to infer intent, some candidates may opt to describe their proposed policies using an A-level vocabulary - whether consciously or subconsciously - perhaps to appear more down-to-earth and less elite. Meanwhile, others may use C-level words to foreground their education background or subject matter expertise. As the curtain closes with Debate 6, it will be interesting to see how our remaining cast of characters craft their last lines.